第三章 进阶篇
HTTP 的实体数据
浏览器
Accept: text/html,application/xml,image/webp,image/png //客户端能接收的数据格式
Content-Type: text/html // 发送的数据类型
Accept-Encoding: gzip, deflate, br //发送数据的压缩格式
Accept-Language: zh-CN, zh, en // 客户端可理解的自然语言
Accept-Charset: gbk, utf-8 // 客户端可以理解的字符集
Accept: text/html,application/xml;q=0.9,*/*;q=0.8 //内容协商权重
服务器
Content-Type: text/html // 响应的数据类型
Content-Encoding: gzip // 响应数据的压缩格式
Content-Language: zh-CN // 响应的自然语言
Content-Type: text/html; charset=utf-8 // 字符集用 charset 标识
Vary: Accept-Encoding,User-Agent,Accept //内容协商特殊的“版本标记”,通常用于代理服务器
HTTP 传输大文件的方法
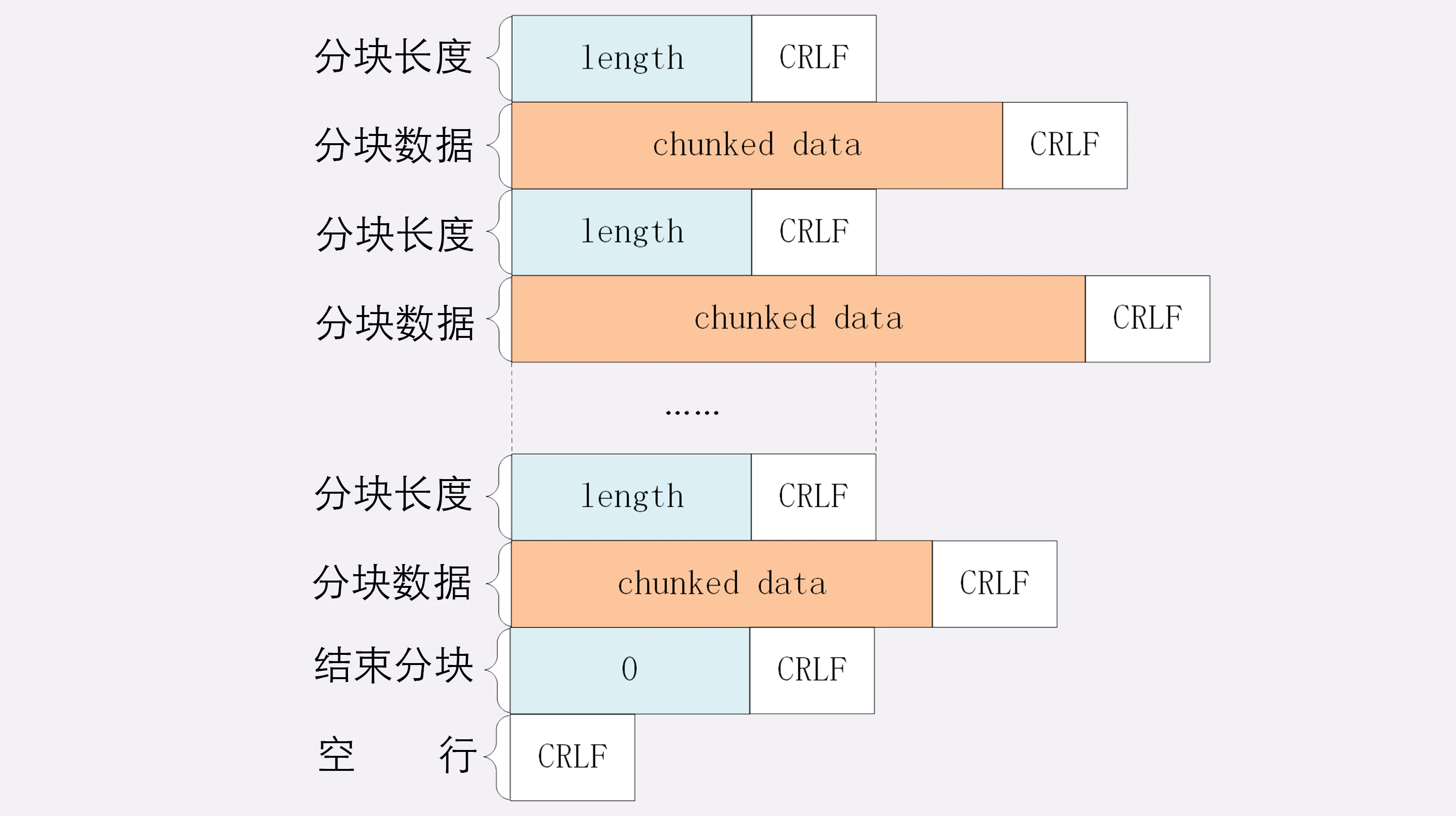
分块传输
分块传输可以流式收发数据,节约内存和带宽,使用响应头字段 Transfer-Encoding: chunked 来表示
分块的格式是 16 进制长度头 + 数据块
服务器 B
Transfer-Encoding: chunked // 分块传输编码
编码规则
范围请求
范围请求可以只获取部分数据,即「分块请求」,实现视频拖拽或者断点续传
使用请求头字段 Range 和响应头字段 Content-Range,响应状态码必须是 206
浏览器
Range: bytes=0-31
服务器
Content-Length: 32 // ! 内容的长度是确定的
Accept-Ranges: bytes // 范围请求
Content-Range: bytes 0-31/96 //范围请求区间
多段数据
也可以一次请求多个范围,这时候响应报文的数据类型是 multipart/byteranges
body 里的多个部分会用 boundary 字符串分隔
Content-Type: multipart/byteranges // !多段数据特殊的数据类型
boundary=xxx // 分隔标记

不分块:HTTP 把客户端需要的东西整个交给 TCP,由 TCP 切块后发送给客户端,客户端接受后在 TCP 层组装完整发给浏览器使用。
分块:HTTP 把客户端需要的东西切分成 块 1、块 2、块 3 到 块 N,然后将 块 1 发给 TCP,TCP 将 块 1 再次切分后发给客户端,客户端接受后在 TCP 组装成 块 1 发给 HTTP 层。然后服务器与客户端用同样的方式发送 块 2、块 3 到 块 N。客户端的 HTTP 在接收完所有块后组装成一个完整的响应。整个过程使用同一个 TCP 连接,块 1 到 块 N 是挨个发送的。
如果是 HTTP2,则基于多路复用技术 块 1 到 块 N 可以同时发送。所以分块抓包 HTTP 只能抓到一个包,如果抓 TCP 的包,分不分块,都会抓到很多包。
分段:分段就是对某个资源的一部分进行请求,类似于把一个大文件切分成很多小文件,类似压缩中的分卷功能,然后客户端只对这些小文件中的一部分进行请求。
分段是对需要哪些资源进行一种说明,分块是一种传输机制,完全不同的两个东西,只是名字比较像。
HTTP 的连接管理
长链接与短链接

浏览器
Connection: keep-alive // 主动请求使用长链接
Connection: close // 主动关闭长链接
Keep-Alive: timeout=value // 约定长链接的关闭时间
服务器
Connection: Upgrade // 配合状态码 101 表示协议升级
Connection: keep-alive // 服务器支持长链接
Connection: close // 服务器将关闭长链接
Keep-Alive: timeout=value // 告知长链接的关闭时间
服务器端通常不会主动关闭连接,但也可以使用一些策略。拿 Nginx 来举例,它有两种方式:
使用
keepalive_timeout指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。使用
keepalive_requests指令,设置长连接上可发送的最大请求次数。比如设置成 1000,那么当Nginx在这个连接上处理了 1000 个请求后,也会主动断开连接。
队头阻塞
「队头阻塞」与短连接和长连接无关,而是由 HTTP 基本的「请求 - 应答」模型所导致的。
因为 HTTP 规定报文必须是「一发一收」,这就形成了一个先进先出的「串行」队列。队列里的请求没有轻重缓急的优先级,只有入队的先后顺序,排在最前面的请求被最优先处理。
性能优化
这在 HTTP 里就是「并发连接」(concurrent connections),也就是同时对一个域名发起多个长连接,用数量来解决质量的问题。
这个就是「域名分片」(domain sharding)技术,还是用数量来解决质量的思路。
HTTP 协议和浏览器不是限制并发连接数量吗?好,那我就多开几个域名,比如 shard1.chrono.com、shard2.chrono.com,而这些域名都指向同一台服务器 <www.chrono.com,这样实际长连接的数量就又上去了,真是“美滋滋”。不过实在是有点“上有政策,下有对策”的味道。>
四通八达:HTTP 的重定向和跳转
Location 字段属于响应字段,必须出现在响应报文里。但只有配合 301/302 状态码才有意义,它标记了服务器要求重定向的 URI,这里就是要求浏览器跳转到 index.html。
服务器
Location: /index.html
- 重定向是服务器发起的跳转,要求客户端改用新的 URI 重新发送请求,通常会自动进行,用户是无感知的;
- 301/302 是最常用的重定向状态码,分别是“永久重定向”和“临时重定向”;
- 响应头字段 Location 指示了要跳转的 URI,可以用绝对或相对的形式;
- 重定向可以把一个 URI 指向另一个 URI,也可以把多个 URI 指向同一个 URI,用途很多;
- 使用重定向时需要当心性能损耗,还要避免出现循环跳转。
让我知道你是谁:HTTP 的 Cookie 机制
写过前端的同学一定知道,在 JS 脚本里可以用 document.cookie 来读写 Cookie 数据,这就带来了安全隐患,有可能会导致“跨站脚本”(XSS)攻击窃取数据。
属性“HttpOnly”会告诉浏览器,此 Cookie 只能通过浏览器 HTTP 协议传输,禁止其他方式访问,浏览器的 JS 引擎就会禁用 document.cookie 等一切相关的 API,脚本攻击也就无从谈起了。
另一个属性“SameSite”可以防范“跨站请求伪造”(XSRF)攻击,设置成“SameSite=Strict”可以严格限定 Cookie 不能随着跳转链接跨站发送,而“SameSite=Lax”则略宽松一点,允许 GET/HEAD 等安全方法,但禁止 POST 跨站发送。
浏览器
Cookie:name=小米;age=20 // 浏览器发送 Cookie
服务器
Set-Cookie:name=小米 // 响应的 Cookie
Set-Cookie:age=20
Expires: // Cookie 的过期的绝对时间
Max-Age: // Cookie 的过期的相对时间,优先级高于 Expires,时间起点是浏览器接收到报文的时间
Domain:www.alrcly.com // 域名作用域
Path:/ // 路径作用域
HttpOnly // 限制 Cookie 只能通过浏览器 HTTP 协议传输
SameSite:Strict // 严格限定 Cookie 不能随着跳转链接跨站发送
SameSite:Lax // 允许 GET/HEAD 等安全方法,但禁止 POST 跨站发送
Secure 限制 Cookie 仅能用 HTTPS 协议加密传输
生鲜速递:HTTP 的缓存控制
浏览器默认的缓存只在“前进”“后退”“跳转”操作中生效,刷是无效的。
服务器的缓存控制
Cache-Control:max-age=30 // 标记资源有效期,单位秒,时间的计算起点是响应报文的创建时刻
Cache-Control:no-store // 不允许缓存
Cache-Control:no-cache // 可以缓存,但在使用之前必须要去服务器验证是否过期
Cache-Control:must-revalidate // 可以缓存,过期之后必须要去源服务器验证是否可以继续使用
客户端的缓存控制
Cache-Control:max-age=0 // 直接过期请求新的数据
Cache-Control:no-cache // 含义和 max-age 一样
条件请求(缓存必备)
服务器
Last-modified // 条件请求的文件的最后修改时间
ETag // 条件请求的资源唯一标识
浏览器
if-Modified-Since // 检查最后修改时间,并判断是否返回资源
If-None-Match // 检查唯一标识,并判断是否返回资源
HTTP 的代理服务
服务器/浏览器(传统协议)
Via:www.aaa.com // 代理信息
X-Forwarded-For:127.0.0.1 // 客户端请求的 IP
X-Forwarded-Host:www.baidu.com // 客户端请求的原始域名
X-Forwarded-Proto:https// 客户端请求的原始协议名
X-Real-IP:127.0.0.1;186.192.1.31 // 代理 IP 信息
代理协议
PROXY TCP4 1.1.1.1 2.2.2.2 55555 80\r\n
GET / HTTP/1.1\r\n
Host: www.xxx.com\r\n
\r\n
这一行文本其实非常简单,开头必须是“PROXY”五个大写字母,然后是“TCP4”或者“TCP6”,表示客户端的 IP 地址类型,再后面是请求方地址、应答方地址、请求方端口号、应答方端口号,最后用一个回车换行(\r\n)结束。
HTTP 的缓存代理
代理
Cache-Control:private // 私有数据不允许缓存
Cache-Control:public // 公开数据可以缓存
Cache-Control:proxy-revalidate // 可以缓存,过期之后可以去代理服务器验证是否可以继续使用
Cache-Control:s-maxage=10 // 代理服务器缓存时间
Cache-Control:no-transform // 不允许进行衍生操作
浏览器
Cache-Control:max-stale=2 // 代理缓存过期可以接受
Cache-Control:min-fresh=1 // 不仅不允许过期,还要求 N 秒之后还是可用的
Cache-Control:only-if-cached // 只接受代理服务器数据,不接受源服务器的响应
代理部分总结

